

This document tries to delve into the question of scientific calculation on GPU (we recommend reading “Why migrate to GPU” beforehand).
Before taking this step, we should have analyzed the following image:
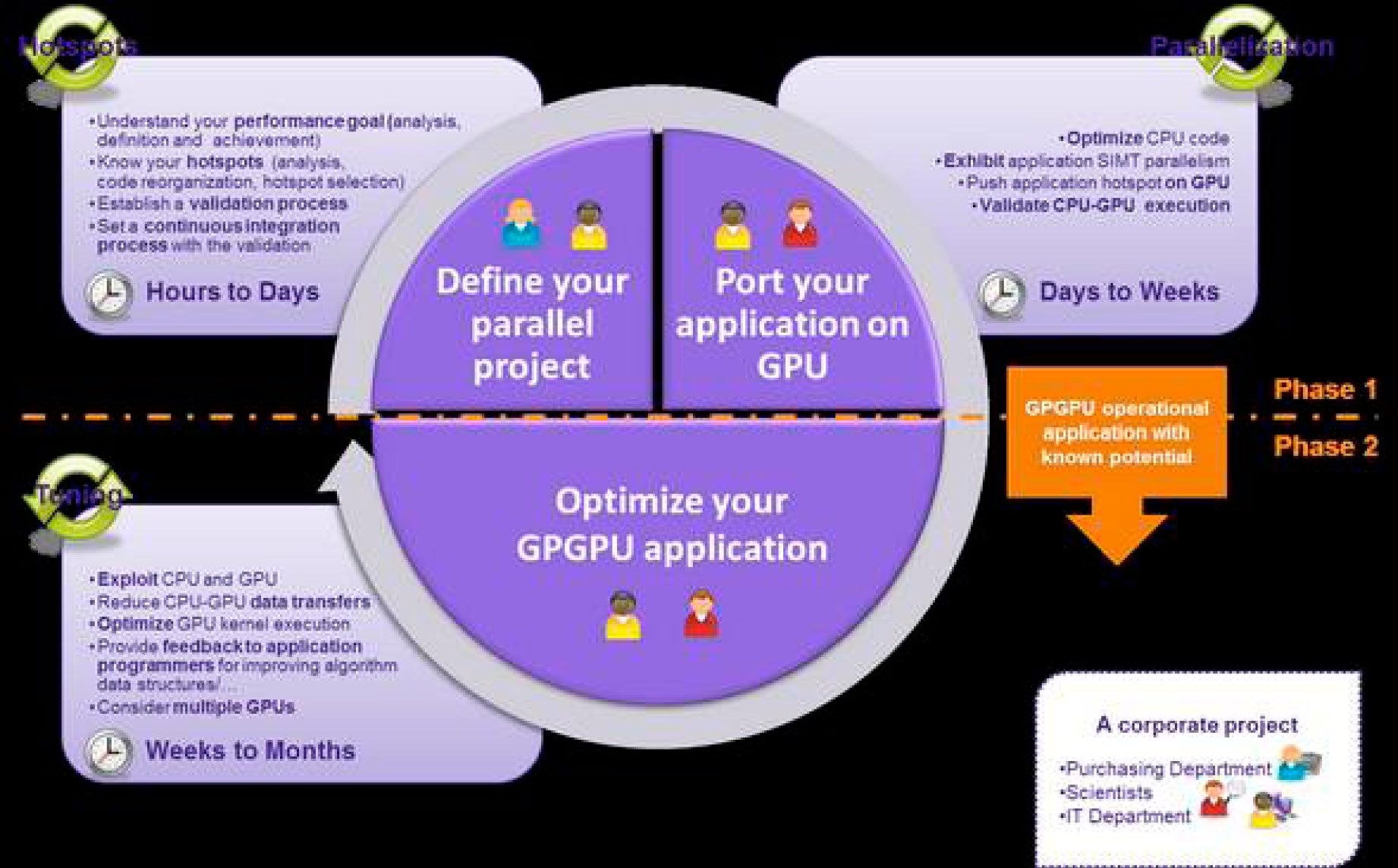
I think this graph is very revealing before we move to GPUs. I like it a lot, because the times can be referred to both the employee to calculate and to develop the application
1. If my code is linear and I haven't started parallelizing it yet, I shouldn't even consider a GPU solution. GPUs always offer more cores than CPUs, but always with fewer features per core (although there are so many, the performance is spectacular) and less memory. That means that I still have a lot of room in the CPUs and a lot of performance to get out of them and that, generation after generation, they will always give me better performance, because the cores are becoming more and faster. effective in Gflops.
We are in the case of the upper left quadrant: if my process is not yet parallel or if it is on a small scale, it is better to focus on optimizing it. Also if it takes hours to a few days, probably buying faster hardware will get me less execution time and save me the human costs of migrating to other platforms.
2…. If my code takes anywhere from a few days to weeks to run, you've probably already tried to parallelize it, at least on one node (Open MP) and to take advantage of the maximum number of cores you have available per server. In this case, we have two options:
- a) We can easily parallelize it in Open MPI and run it on several nodes. Either split it into different separate processes and launch it to different nodes or parallelize it between several nodes through a low latency network, the most widespread being Infiniband. Advantage: few programming changes. Disadvantage: more investment in hardware and light consumption.
- b) Analyze that 25% of my application consumes 90% of the time and try to migrate this part of the code to GPU. Advantage: savings on hardware, software (if you use pay-per-node development tools) and electricity. Disadvantage: significant migration effort.
3. Lower half of the image. If our calculation takes weeks to months, we really need a lot of effort. The solution comes hand in hand with technologies such as OpenACC or CUDA with tools such as CAPS HMPP Workbench, that is, mixed CPU-GPU programming, where we make the most of the power of the system or multi-programming. GPU. In this scenario, the move to GPU becomes essential.
Well, let's imagine that we have already decided to migrate to GPU. Basically we are clear that our x86 code is not going to run on any GPU (at least without tweaking), because only the base processor directly runs x86 calculations.
Before going into the matter, I will say that in SIE whenever we think of scientific calculation, we are talking about the Linux operating system, although there are some applications also available in Windows, it is the environment with the highest performance and the most stable. If we go to GPUs for this reason, it seems logical to use the most optimal system.
Let's start, before going into the technologies, to talk about the tools that are available for development on GPU. We will start talking from the most difficult to the easiest:
- OpenCL (it would be similar to the OpenGL standard for 3D graphics), that is, it works for any of the 3 technologies that we will mention, but it is the hardest to use: working in C/C++, the soonest. As much as machine code and with few programming aids, in addition to requiring more lines of code to be thrown away. Advantages: we can develop for any of the platforms and probably with the best possible code optimization. Certainly there are libraries like OpenCV (computer vision) or others that can make our lives easier.
- CUDA: It stands for Compute Unified Device Architecture and can be used with Python, Fortran and Java instead of C/C++. It is a de facto standard. What do we understand by this concept? A standard (because it is widespread in the market), but which is owned by a company (it is not an IEEE or Open Source standard). This does not mean that the company does not share it with the community or with other developers. Another typical example of a de facto standard is the pdf format, owned by Adobe. It was developed by NVDIA in 2007. From version 1.0 to the current 5.5 (6.0 is already released), it has been compatibility has been maintained, so any previously developed software continues to work. Each time it has been incorporating better SDKs (development kits) and currently it is the one that has the most libraries, scientific calculation applications in many fields (currently more than 70) and development aid for everything. type (currently more than 4.000 scientific papers refer to CUDA)
- "Parallel Studio" and "Cluster Studio": Tools that integrate the Fortran/C++ compiler from the Intel company with libraries and development kit. Basically, they are the only ones that offer a migration from CPU to “GPU” (they are more properly said coprocessors), without the need to rewrite the code. The reason is that the coprocessors (which come with a PCI-Express connection) like the rest of the solutions, however, are still x86 compatible.
FUTURE: OpenACC
Promoted by companies such as Caps, Cray Corporation, Nvdia or Porland Group, an open source standard emerges, which includes a series of common directives, which allow working on any of the platforms and what is more important Looking to the future, do mixed CPU-GPU programming, which is supposed to be the new paradigm in the HPCC (high performance Computing Calculus) world. The only drawback is its recent launch, since it is a platform that is not yet mature.

Once this is assumed, we have three possibilities or technologies that are offered to us (I list them from the least implemented for calculation to the most implemented):
ATI (AMD)
Absorbed this company by the second manufacturer of PC processors, it manufactures plates that perhaps in terms of benefits are the most superior. What drawbacks does it pose? Well, the big drawback is that ATI has not made a great effort to release development tools and that means that it is necessary to program in OpenCL and it is complicated. The series intended for calculation is the ATI Radeon HD.
It is true that since AMD has released APUs (hybrids between CPU and GPU) that can be integrated directly on the board, it allows hybrid programming and when the tools are powerful enough for it, it may be an important option to consider. In addition, at the moment there are only uniprocessor systems, which limits the number of cores and memory.

INTEL PHI
Previously called MIC (multicore), which I deliberately avoid calling it Xeon Phi, so as not to make mistakes with the processors
Intel Xeon motherboard, whose power per core is much higher than the 60 cores offered by the Phi. The beauty of this technology is that it is not necessary to rewrite the application. Being x86 compatible, according to Intel with the Parallel Studio and Cluster Studio tools, applications can be migrated automatically. The problems are three:
- These tools are paid and quite expensive, even for the university environment
- Migrating applications with the default tools and debuggers only achieves on the order of twice the speed of the motherboard processor. This is not worth it.
- If we really want to obtain between 5 and 10 times what Intel offers, we must reprogram as in the other scenarios and therefore we are in the same problem.

NVIDIA TESLA AND GTX
We will start by clarifying that NVDIA is a commercial house and that CUDA is its de facto standard in the market, but proprietary. It is currently the most mature technology, since it is going through the CUDA 6 version and since the CUDA 1 version, although it has been improving, it has maintained compatibility.

The main advantage it has are three:
- There are more than 70 applications on the market that use the CUDA standard, including some Spanish ones such as Octopus, ACMD and River Flow 2D. Of the most important and that give the best performance, it is worth highlighting Amber, NAMD and Cromacs. Of the most well-known migrated tools, Mathlab and Matematica (not in all their functions, but in the most important ones), languages like Pyton, libraries like OpenCV, etc.
You can download the full list at gpu-accelerated-applications-for-hpc - The performance is very well optimized both using the most expensive range and focused on scientific calculation such as Tesla, as well as the most economical range that is GEFORCE GTX (classically used for games) on cards that in many cases give almost better result as the Titan Black.

- The tools and libraries offered by CUDA are completely free for any type of development.

Therefore, and to summarize, if your application is migrated to CUDA or the tool you use to develop it is, it is a perfect option and you will be able to obtain with the latest models a performance improvement of between 5 and 50 times, depending on your application.
Finally, we want to draw a conclusion from this entire report. If your research group is not very large, better stay in the CPU environment for now. They will continue for a few years giving more and more performance and therefore you will be able to continue taking advantage of the improvements, but think that sooner or later they will incorporate GPUs on the chip and you will have to get used to this programming environment, therefore take advantage of it.
If your application has already been ported to GPUs, take advantage of it. Some applications manage to reduce the calculation time from 28 days to a few hours. With a single machine you can do what an entire cluster could do and with a cluster of GPUs what a supercomputing center did a few years ago.
If you already have high-level (human-friendly) tools for GPU programming, take advantage of this new technology, with tools like Mathlab by Mathworks (more than 200 functions migrated) or Mathematica Wolfram it is relatively simple.
To provide specific data, researchers who already work with applications on GPUs, give us specific data:
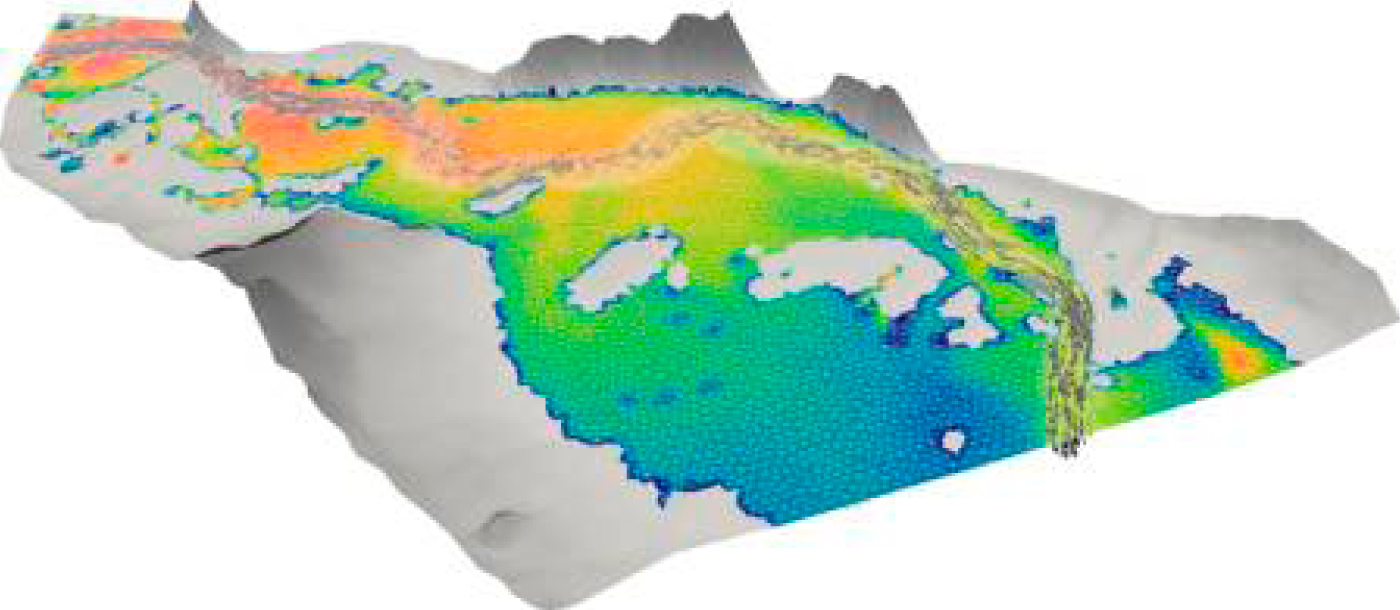
- River Flow 2D Plus GPU application (developed by the University of Zaragoza): For a certain calculation on CPU that takes 28 days on GPU it drops to 8 days
- Tests carried out by Dr. Jordi Faraudo from the Autonomous University of Barcelona: NAMD simulation application with 20500 volumes: speed 2 GPU Titan black: 0.0281269 days/ns
- For other applications like Amber you can see the comparison in our first document "Why migrate from CPU to GPU
Think that GPUs are not only a time saver, but also energy and space savings, which is becoming a very important element.