

Este documento, intenta profundizar en la cuestin del clculo cientfico en GPU (recomendamos leer previamente “Porque migrar a GPU”).
Antes de dar este paso, deberamos haber analizado la imagen siguiente:
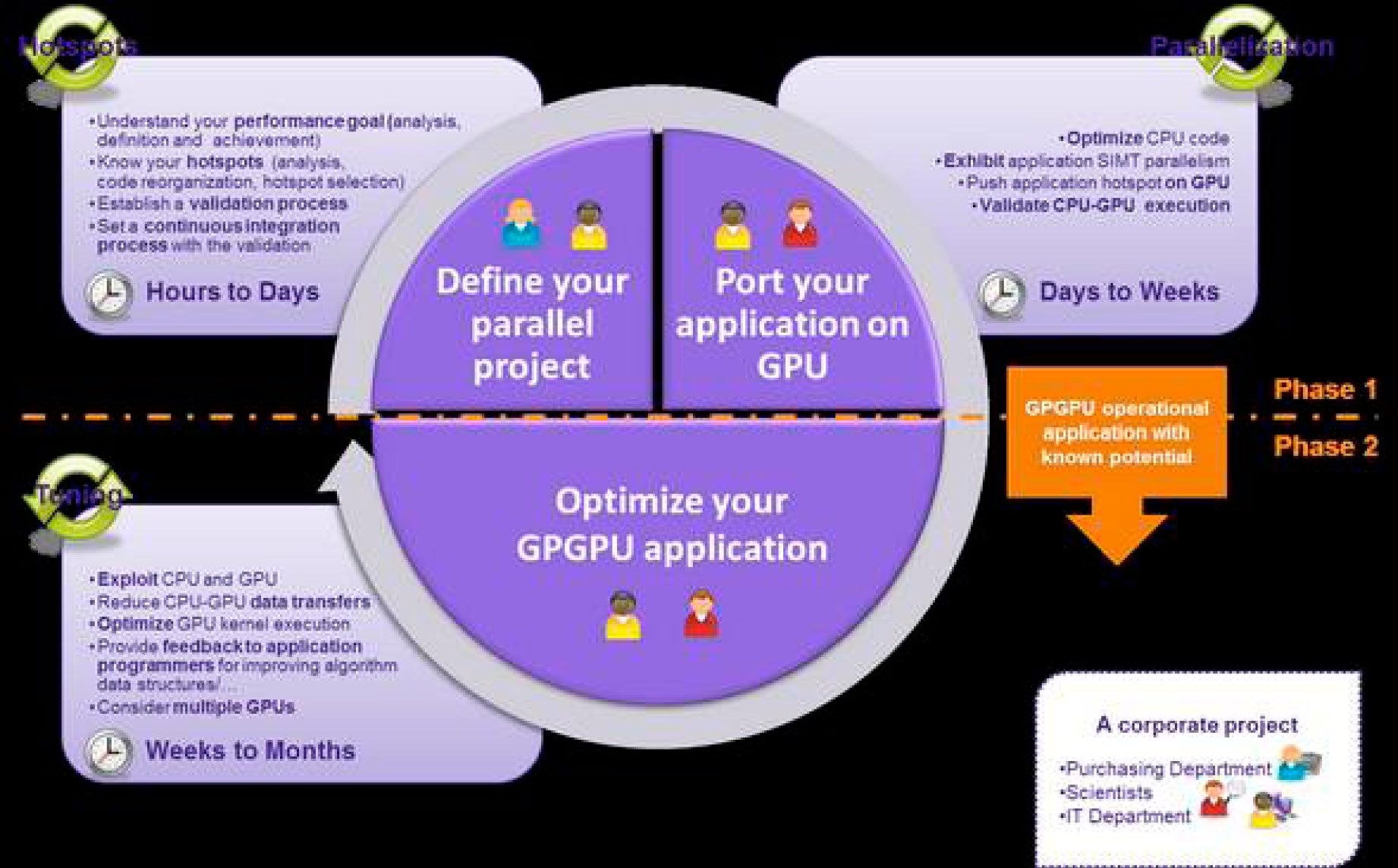
Creo que este gráfico, es muy revelador antes de dar el paso hacia las GPUs. Me gusta mucho, porque los tiempos pueden estar referidos tanto al empleado para calcular como para desarrollar la aplicación
1. Si mi código es lineal y todavía no he empezado por paralelizarlo, no debera ni tan siquiera plantearme una solución de GPU. Las GPUs ofrecen siempre ms cores que las CPUs, pero siempre con menos prestaciones por core (aunque al ser muchos, el rendimiento es espectacular) y menos memoria. Eso significa que todavía tengo mucho campo en las CPUs y mucho rendimiento que sacarles y que además generación tras generación, siempre me darán mejores prestaciones, porque los núcleos cada vez son más y de mayor velocidad efectiva en Gflops.
Estamos en el caso del cuadrante superior izquierdo: si mi proceso no es todavía paralelo o si lo es a pequea escala, mejor centrarme en optimizarlo. Además si tarda de horas a unos pocos das, probablemente comprando un hardware ms rpido consiga menos tiempo de ejecución y me ahorre los costes humanos de migrar a otras plataformas.
2 . Si mi código tarda en ejecutarse de unos das a semanas, probablemente ya haya tratado de paralelizarlo, al menos en un nodo (Open MP) y de aprovechar el máximo nmero de núcleos que tenga disponible por servidor. En este caso, tenemos dos opciones:
- a) Fácilmente podremos paralelizarlo en Open MPI y correrlo en varios nodos. Bien trocearlo en distintos procesos separados y lanzarlo a nodos distintos o paralelizarlo entre varios nodos a través de una red de baja latencia, la más extendida Infiniband. Ventaja: pocos cambios de programación. Inconveniente: más inversión en hardware y consumo de luz.
- b) Analizar que 25% de mi aplicación consume el 90% del tiempo e intentar migrar esta parte del código a GPU. Ventaja: ahorro en hardware, software (si usa herramientas de desarrollo de pago por nodo) y luz. Inconveniente: esfuerzo importante de migración.
3. Mitad inferior de la imagen. Si nuestro cálculo tarda de semanas a meses, realmente necesitamos un gran esfuerzo. La solucin viene de mano de tecnologías como OpenACC o CUDA con herramientas como CAPS HMPP Workbench, es decir, de programacin mixta CPU-GPU, donde aprovechemos al máximo la potencia del sistema o de programación multi-GPU. En este escenario, el paso a GPU se hace imprescindible.
Bueno, imaginemos que ya hemos decidido migrar a GPU. Básicamente tenemos claro, que nuestro cdigo x86 no va a correr en ninguna GPU (al menos sin retoques), porque solo el procesador base corre directamente cálculos x86.
Antes de entrar en materia, diré que en SIE siempre que pensamos en cálculo científico, estamos hablando de sistema operativo Linux, aunque existen algunas aplicaciones tambin disponibles en Windows, es el entorno de más rendimiento y más estable. Si acudimos a las GPUs por este motivo, parece lógico usar el sistema más óptimo.
Empecemos, antes de entrar en las tecnologías a hablar de las herramientas que hay para desarrollo sobre GPU. Empezaremos hablando desde las más difciles a las más fáciles:
- OpenCL (sera similar al estándar OpenGL de grficos 3D), es decir, vale para cualquiera de las 3 tecnologías que mencionaremos, pero es el más duro de usar: trabajar en C/C++, lo más próximo al código máquina y con pocas ayudas a la programación, además de que exige tirar más lneas de código. Ventajas: podemos desarrollar para cualquiera de las plataformas y probablemente con la mejor optimización de cdigo posible. Ciertamente existen librerías como OpenCV (visión artificial) u otras que pueden hacernos la vida más fácil.
- CUDA: Son las siglas de Compute Unified Device Architecture (Arquitectura Unificada de Dispositivos de Cálculo) y se puede usar con se puede usar Python, Fortran y Java en vez de C/C++. Es un estándar de facto. Que entendemos por este concepto? Un estndar (porque está muy extendido en el mercado), pero que es propiedad de una compañía (no es un estndar IEEE ni Open Source). Esto no quiere decir que la compañía no lo comparta con la comunidad ni con otros desarrolladores. Otro ejemplo tpico de estándar de facto es el formato pdf, propiedad de Adobe.Fue desarrollado por NVDIA en el 2007. Desde la versión 1.0 a la 5.5 actual (la 6.0 ya est recin lanzada), se ha mantenido la compatibilidad, con lo que cualquier software desarrollado anteriormente sigue funcionando. Cada vez ha ido incorporando mejores SDK (kit de desarrollo) y en la actualidad es la que dispone de más librerías, aplicaciones de cálculo científico en muchos campos (actualmente más de 70) y ayudas al desarrollo de todo tipo (actualmente más de 4.000 “papers” cientificos hacen referencia a CUDA)
- “Parallel Studio” y “Cluster Studio”: Herramientas que integran el compilador Fortran/C++ de la compañía Intel con librerías y kit de desarrollo. Básicamente son los únicos que ofrecen una migración de CPU a “GPU” (son más propiamente dichos coprocesadores), sin necesidad de reescritura del código. El motivo es que los coprocesadores (que vienen con conexión PCI-Express) al igual que el resto de soluciones, sin embargo siguen siendo compatibles x86.
FUTURO: OpenACC
Impulsado por compañías como Caps, Cray Coorporation, Nvdia o Porland Group, surge un estándar de código libre, que incluye una serie de directivas comunes, que permitir trabajar en cualquiera de las plataformas y lo que es más importante, cara al futuro, hacer programación mixta CPU-GPU, que se supone ser el nuevo paradigma en el mundo HPCC (high performance Computing Calculus). La única pega es su reciente lanzamiento, dado que es una plataforma todavía poco madura.

Una vez asumido esto, tenemos tres posibilidades o tecnologías que se nos ofrecen (las enumero de las menos implantadas para cálculo a las más implantadas):
ATI (AMD)
Absorbida esta compaa por el segundo fabricante de procesadores de PC, fabrica placas que quizá en prestaciones son las más superiores. Que inconvenientes plantea? Bueno, la gran pega es que ATI no ha hecho un gran esfuerzo en sacar tools de desarrollo y eso se traduce en que es necesario programar en OpenCL y resulta complicado. La serie destinada a cálculo es las ATI Radeon HD.
Es cierto, que dado que AMD ha lanzado las APU (hibridos entre CPU y GPU) integrables directamente en placa, permite programación híbrida y cuando las herramientas sean lo suficientemente potentes para ello, puede que sea una opción importante a considerar. Adems de momento solo existen sistemas monoprocesador, lo que limita el número de cores y la memoria.

INTEL PHI
Anteriormente denominada MIC (multicore), que evito a posta denominarla Xeon Phi, para no incurrir en equívocos con los procesadores
Intel Xeon de placa madre, cuya potencia por core es muy superior a los 60 cores que ofrece la Phi. Lo atractivo de esta tecnología es que no es necesario reescribir la aplicación. Al ser compatible x86, segn Intel con las herramientas Parallel Studio y Cluster Studio, se pueden migrar las aplicaciones de forma automática. Los problemas son tres:
- Estas herramientas son de pago y bastante costosas, incluso para el entorno universitario
- Si se migran las aplicaciones con las herramientas y depuradores por defecto, solo se consigue del orden de dos veces la velocidad que obtiene el procesador de la placa base. Esto no compensa.
- Si realmente queremos obtener entre 5 y 10 veces como ofrece Intel, debemos reprogramar como en los otros escenarios y por tanto estamos en la misma problemática.

NVIDIA TESLA Y GTX
Empezaremos aclarando que NVDIA es una casa comercial y que CUDA es su estándar de facto en mercado, pero propietario. Actualmente es la tecnología más madura, ya que va por la versión CUDA 6 y desde la versión CUDA 1, aunque ha ido mejorando, ha mantenido la compatibilidad.

La ventaja principal que tiene son tres:
- Existen más de 70 aplicaciones en mercado que usan el estándar de CUDA, entre ellas incluso algunas espaolas como Octopus, ACMD y River Flow 2D. De las ms importantes y que mejor rendimiento dan cabe destacar Amber, NAMD y Cromacs. De las herramientas migradas más conocidas Mathlab y Matematica (no en todas sus funciones pero si en las ms importantes), lenguajes como Pyton, libreras como OpenCV, etc.
Puede descargar la lista completa en gpu-accelerated-applications-for-hpc - El rendimiento est muy bien optimizado tanto usando la gama más cara y enfocada a clculo científico como es Tesla, como la gama más económica que es GEFORCE GTX (usada clásicamente para juegos) en tarjetas que en muchos casos dan casi mejor resultado como la Titan Black.

- Las herramientas y librerías ofrecidas por CUDA, son totalmente gratuitas para cualquier tipo de desarrollo.

Por tanto, y por resumir, si su aplicación esta migrada a CUDA o la herramienta que usa para desarrollar lo estén, es una opción perfecta y podrá obtener con los últimos modelos una mejora de rendimiento de entre 5 y 50 veces, según sea su aplicación.
Para terminar, queremos sacar una conclusin de todo este informe. Si su grupo de investigación no es muy numeroso, mejor quédese en el entorno de CPUs de momento. Seguirán unos cuantos aos dando cada vez más rendimiento y por tanto podrá seguir aprovechando las mejoras, pero piense que tarde o temprano irán incorporando GPUs en el chip y tendrá que irse acostumbrando a este entorno de programación, por tanto aproveche para ello.
Si su aplicación ya migrada para GPU, aprovechese. Algunas aplicaciones consiguen reducir el tiempo de cálculo de 28 das a unas pocas horas. Con una sola máquina podrá hacer lo que un clúster entero y con un clúster de GPUs lo que hace unos años hacía un centro de supercomputacin.
Si ya dispone de herramientas para programar en GPU y que son de alto nivel (fáciles de usar para el ser humano), aproveche esta nueva tecnología, con herramientas como Mathlab by Mathworks (más de 200 funciones migradas) o Mathematica Wolfram es relativamente sencillo.
Para aportar datos concretos, investigadores que ya trabajan con aplicaciones en GPUs, nos dan datos concretos:
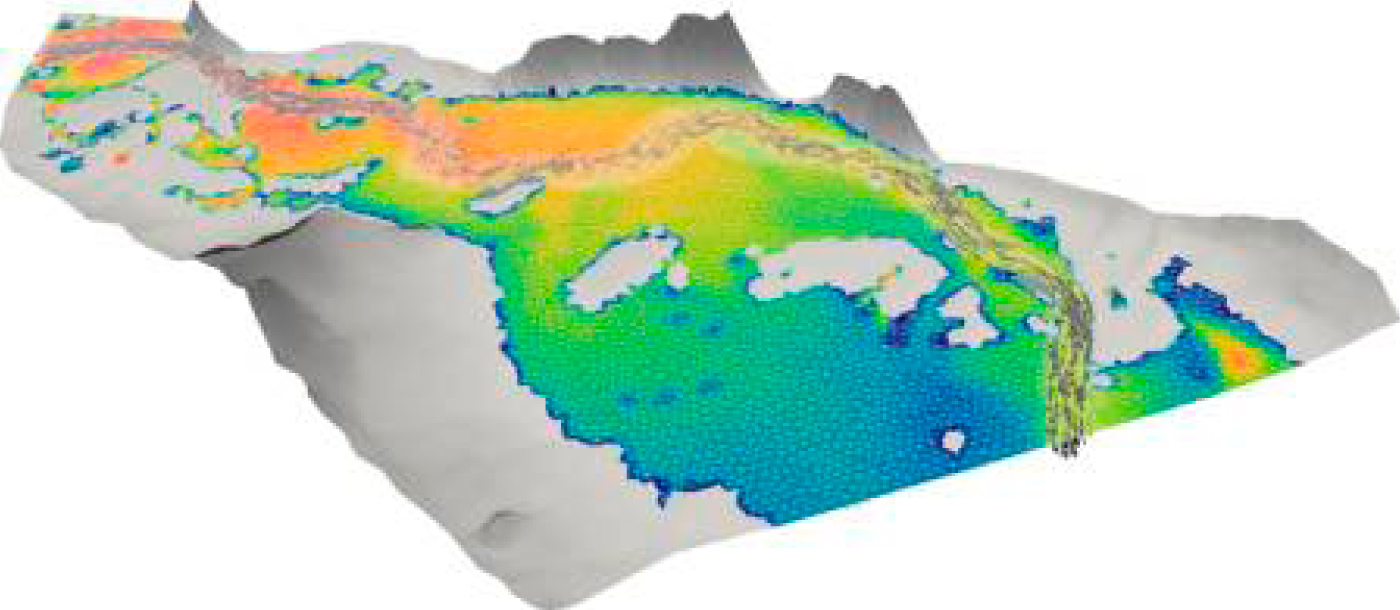
- Aplicación River Flow 2D Plus GPU(desarrollada por la Universidad de Zaragoza):Para un determinado cálculo sobre CPU que tarda 28 das sobre GPU baja a 8 días
- Pruebas realizadas por el Dr. Jordi Faraudo de la Universidad Autónoma de Barcelona: Aplicación simulación NAMD con 20500 tomos: velocidad 2 GPU Titan black : 0.0281269 days/ns
- Para otras aplicaciones como Amber pueden ver la comparativa en nuestro primer documento “Porque migrar de CPU a GPU
Piense que las GPUs no solo son un ahorro de tiempo, sino un ahorro de energía y espacio, que empieza a ser un elemento muy importante.